
How to Design a Self-Healing, Dynamic-Size Raft Cluster in Go
When wanting to build a distributed cluster with a shared state and leader election, one may quickly come across the Raft replication algorithm. It has become the backbone in a handful of distributed databases such as TiDB or also service discovery tools such as Consul. Essentially, it provides a straightforward API to keep data consistent across nodes, so that software engineers can focus on other aspects of their project.
In my case, I required Raft for a tool that would manage another distributed database, RonDB, and be placed on each respective RonDB node. When I started using hashicorp’s Go library for Raft, I had 3 requirements:

- A highly available leader running a reconciliation (/control) loop towards a declarative state and persisting state
- Dynamic & self-healing cluster size (since RonDB is horizontally scalable)
- Self-contained cluster; i.e. not having ingress network access to any nodes
Most of this may sound like a great Kubernetes use-case, but the stack I was dealing with was not containerised and was therefore using VMs. In this article I’ll thereby be describing a minimal example of how these requirements can be fulfilled using the mentioned Raft library. At its core, this blog post shows how to use the Raft API to carefully automatise adding and removing nodes to a Raft cluster. All code is available on GitHub. And for the record, the original project “Managed RonDB” can be run locally here.
Reconciliation Loop
In order to best handle the requirement of having a network with no ingress access, we will be using a declarative protocol to tell the leader Raft node in which desired state we want to see the cluster in. This means that the cluster takes full control of the type & order of actions it needs to take to move towards the desired state. The user (later called “api-server”) thereby also needs no knowledge about the cluster’s internal state.
The term “reconciliation loop” means that the leader node in the cluster will continuously observe the internal state, compare it with the desired state and then take any required actions if it notices that two have diverged. In our implementation, it will only check for new desired states, once the current internal state has converged with the last accepted desired state.
func RunLoop() error {
ticker := time.NewTicker(3 * time.Second)
for {
select {
case <-ticker.C:
if !AreAtDesired() {
workTowardsDesired()
}
getNewDesired()
}
}
}In our case, the internal state will consist of the number of servers registered in the Raft configuration, whilst the desired state consists of the number of replicas the user wishes to have. These values basically mean the same thing.
// If we are not at desired, we work towards it
func(raftObj *raft.Raft, desiredState DesiredState) AreAtDesired(bool, error) {
future := raftObj.GetConfiguration()
if err := future.Error(); err != nil {
return false, err
}
config := future.Configuration()
return desiredState.NumberReplicas == len(config.Servers), nil
}Controlling the Cluster
In order to steer the Raft cluster, we will be implementing a basic REST API web server that we have direct access to. This api-server will implement 3 REST API endpoints which the nodes in the Raft cluster can call:
GET /desired_state
// Reponse payload
type DesiredState struct {
NumberReplicas uint8
}This API allows the user to tell the cluster in which desired state they would like to see it in. Here, the desired state is very simple — it is the number of Raft nodes we wish to see. We can thereby use it to scale the cluster up and down. If a node dies accidentally, the reconciliation loop should take of adding a new node again (self-healing).
POST /desired_hosts
// Request payload
type NumDesiredHosts uint8Whenever the leader notices that it has diverged from the desired state, it can request hosts from the api-server. The api-server must then make sure that this (total) amount of hosts is running. In a more complex scenario, this also becomes a form of desired state, where the api-server continuously checks whether this amount of hosts is up and running. Also, in reality, there might be a lot more specifications to what kind of hosts the cluster needs (e.g. availability zone, memory, etc.).
GET /current_hosts
// Reponse payload
type CurrentHosts []stringThe current hosts correspond to all hostnames in the Raft cluster. Every Raft node starting up can GET the current hosts in order to understand the cluster topology. More to this later.
Raft Nodes Joining and Leaving the Cluster
An important part to understand in Raft is that:
- Only the leader can add or remove nodes from a cluster
- The leader will call out a leader election if it cannot heartbeat a majority of nodes in the cluster. This is because the leader sees a risk that it might be in a minority network partition.
Due to these factors, we will use an architecture where each node autonomously contacts the leader both at startup and cleanup to request to join or drop out of the Raft cluster. Let’s look into why each of these two cases proves useful in contrast to giving the leader full responsibility of adding/removing nodes.
- Joining cluster:
By actively contacting the leader before joining the cluster, we can control that the node is ready before the leader starts heartbeating towards it. In a situation where we might add multiple nodes in parallel and they are not ready before heartbeating, the leader can lose leadership if these new nodes make up a majority. We can even run into difficulties if this is the second (2/2) node.
- Leaving cluster:
When running a cluster, it is always possible for nodes to be killed for unplanned reasons. If we don’t have a majority of nodes left, the leader will give up leadership. By attempting to de-register before going down, we potentially avoid the leader calling out an unwinnable leader election.
// Requesting to join and leave cluster in main.go
// Catch any interrupt signal here
// Beware of timeouts before uncatcheable SIGKILL is sent
// Timeout is 10s for Python's Docker library
quit := make(chan os.Signal, 1)
signal.Notify(quit, syscall.SIGINT, syscall.SIGTERM, syscall.SIGABRT)
raft_api.RequestJoinCluster()
// Important!
defer raft_api.RequestLeaveCluster()
select {
case <-quit:
return
case <-leaderChannel
log.Info("We're leader now!")
reconciliationLoop()
}Giving every node responsibility to join the cluster by themselves, creates the requirement for the endpoint GET /current_hosts, as previously described. Using this endpoint, the follower can ask around, to see who the leader is and then ask the leader whether it can join. The latter functionality is enabled by making the Raft API accessible to external nodes via gRPC endpoints.
syntax = "proto3";
// A mapping of the Raft API for gRPC functions
service RaftApi {
rpc LeaderWithID (Empty) returns (LeaderWithIDReply) {}
rpc AddVoter (AddVoterRequest) returns (Empty) {}
rpc RemoveServer (RemoveServerRequest) returns (Empty) {}
rpc DemoteVoter (RemoveServerRequest) returns (Empty) {}
}
message Empty {}
message LeaderWithIDReply {
string ServerID = 1;
string ServerAddress = 2;
}
message AddVoterRequest {
string ServerID = 1;
string ServerAddress = 2;
uint64 PrevIndex = 3;
}
message RemoveServerRequest {
string ServerID = 1;
uint64 PrevIndex = 2;
}Generally, it can also be helpful to keep Raft replication and the reconciliation/business logic as separate as possible for the sake of code simplicity. If the leader were fully responsible for adding & removing nodes, one would always have to write additional code for the edge-case where it is removing itself. This may for example happen in order to scale down. The alternative is to keep the reconciliation loop completely idempotent, so that any other new leader can just continue where the last leader “failed”.
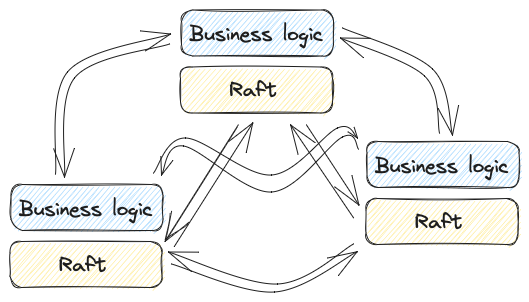
Raft State & Dependencies
The Raft state that the leader will be persisting will also be kept simple: It will be the last accepted desired state. In our implementation, each Raft log will thereby overwrite the entire Raft state. For bigger states, this is probably not recommended.
Lastly, regarding Raft dependencies, we will be using BoltDB as our Raft storage engine and gRPC as our transport protocol between nodes.
// Simplified go.mod
require (
github.com/Jille/raft-grpc-transport v1.4.0
github.com/hashicorp/raft v1.5.0
github.com/hashicorp/raft-boltdb v0.0.0-20230125174641-2a8082862702
google.golang.org/grpc v1.40.0
google.golang.org/protobuf v1.27.1
)Test Setup
We will run our setup entirely within Docker in order to simulate a closed network and to simplify our node overview + reproducibility. We will create one API web-server container, which will implement the 3 HTTP endpoints mentioned earlier. It will let us forward a desired state by mounting a JSON file to the container. It will also add/remove containers by using the mounted the Docker socket. In order to start the cluster, we will create a bootstrap container, which will fetch the first desired state. These two first containers can be summarised in a Docker Compose file. Keep in mind our API server actively has to add new containers it spawns to the Docker Compose network.
# Simplified Docker Compose file
version: '3.7'
services:
api-server:
build: ./api-server
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./desired_state.json:/home/desired_state.json
bootstrap_raft:
build: ./raft-node
environment:
BOOTSTRAP_HOST: "true"
networks:
default:
attachable: trueRunning a cluster
So, let’s have a go at running our code, with the NumberReplicas set to 3 in the desired_state.json file:
>> docker-compose up
After around 10s, we should be seeing 2 new containers (4 in total) spawned. Now let’s kill two of our Raft containers. Feel free to kill the bootstrap container. Again, after 10–15s we should be seeing 2 new containers once again. The self-healing process is thereby proven. Nice! ✌🏼
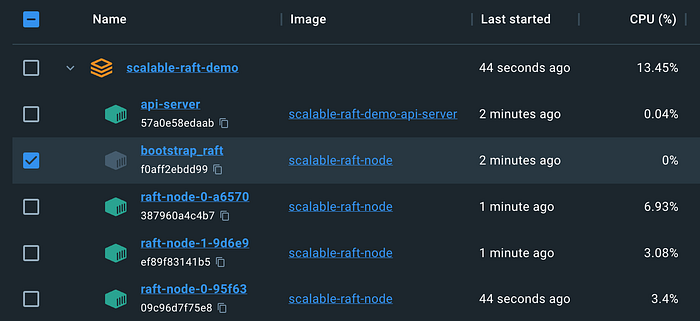
Now, let’s increase the number of desired replicas to 6 in our JSON file. Once again, after 10–15s, we should be seeing 6 Raft containers up and running. Lastly, we can decrease the number of replicas again. The corresponding number of containers should then be programmatically stopped. Scaling up and down is therefore also proven! Awesome! 😊
// Logs of a new leader being elected after another goes down
[WARN] heartbeat timeout reached, starting election: last-leader-addr=raft-node-0-a6570:8000 last-leader-id=raft-node-0-a6570
[INFO] entering candidate state: node="Node at raft-node-1-d65c8:8000 [Candidate]" term=6
[INFO] election won: term=6 tally=3
[INFO] entering leader state: leader="Node at raft-node-1-d65c8:8000 [Leader]"A weakness of this implementation is that the nodes may not always be able to clean up their Raft membership in time before being killed. It is up to you whether you want to add a timeout where the leader removes unresponsive nodes from a cluster. This is not done here.
Next Level: Rolling Restarts / Temporary Drop-outs
In our specific project, another requirement was to be able to cause rolling restarts of the nodes running Raft. This was mostly for online software upgrades after having replaced the binaries running the nodes (old school upgrade I know 🙄).
Since this feature requires a fair amount of additional code, it is only briefly described here and not handled in the GitHub repository. It is however runnable in the original project here.
In practice what this feature means, is that the leader tells one node after another to restart itself. With a restart policy “on-failure”, the node can receive this call from the leader, exit with a non-zero exit code and thereby be restarted. At the end, the leader runs this call on itself and thus inherently passes on leadership.
If we followed our strategy so far, we would entirely remove and re-add nodes to the Raft cluster. Doing so, one would run into a couple of issues:
Problem 1: A node that restarts, reads its persisted Raft state and believes that it is still part of the cluster, since the leader does not actively inform a follower when it is removing it from the cluster. The node thereby immediately expects heartbeats from the last registered leader, which does not happen, since the leader has not registered it yet. The follower then calls out a leader election.
Problem 2: Adding a node to a cluster immediately makes it a potential voter in elections. Since the node may have missed a few logs since being down, it requires to be updated with the latest logs. In unlucky cases, sending both past logs and heartbeats may cause a network bottleneck and cause the follower OR leader to call a leader election.
Problem 3: If the first two issues are handled by increasing heartbeat timeouts, having to restart multiple nodes in serial may cause another timing problem. Since the reconciliation loop logic is so far unaware of whether the last restarted node has fully updated its Raft logs, it may trigger the next restart too early, causing an additional network bottleneck. Of course, this can also be handled by increasing heartbeat timeouts, but this is generally not recommended.
Thankfully, our Raft library comes with the following additional features, each corresponding to the listed problem:
Solution to Problem 1: It is possible to simply “demote” a voter, without removing it from a cluster. This means that the leader will continue to send it heartbeats and logs, but not take it into account for leader elections. When a node is restarted, it thereby immediately receives heartbeats again and does not call out a leader election. It will also be aware that it is not a voter when reading its Raft state.
// Raft's function signature of "demoting" a voter
func (*raft.Raft).DemoteVoter(
id raft.ServerID,
prevIndex uint64,
timeout time.Duration,
) raft.IndexFutureSolution to Problem 2: It is possible to compare the LastIndex with the AppliedIndex on the restarted node to check whether it has caught up with the logs. Once it has, it can safely request to be added as a voter again.
for {
select {
case <-time.After(300 * time.Millisecond):
if raft.AppliedIndex() != raft.LastIndex() {
continue
}
}
logger.Info("Our indices have caught up, we can join the Raft cluster!")
break
}Solution to Problem 3: We can create Raft “Observers”, which notify us when defined events happen. This means that the leader can actively listen to a node stopping (and then resuming) to respond to heartbeats. Arbitrary sleeps are therefore replaced with perfectly timed function logic. This however means that we will have to start mixing the reconciliation logic with the Raft logic. Tough luck.
// Code deep inside reconciliation loop;
// Leader waiting for peer to disconnect
// Register for obervation
failHeartbeatChannel = make(chan raft.Observation)
observerFailedHB := raft.NewObserver(
failHeartbeatChannel,
false,
func(o *raft.Observation) bool {
if failed, ok := o.Data.(raft.FailedHeartbeatObservation); ok {
return string(failed.PeerID) == "ID-peer-to-die"
}
return false
},
)
raftInstance.RegisterObserver(observerFailedHB)
defer raftInstance.DeregisterObserver(observerFailedHB)
// Wait for observation to happen
select {
case <-failHeartbeatChannel:
a.Log.Info("Observed that follower missed heartbeats")
case <-time.After(15 * time.Second):
return errors.New("waiting for peer to miss a heartbeat timed out")
}What’s missing are implementation details, which are out of scope of this blog post. Briefly:
- Adding a field in the desired state to trigger restarts (e.g. a logical clock
RunningSince) - Letting every node keep track of when it was restarted last, to make sure we have reached the desired state; also, persist this in the Raft log state
- Making sure the bootstrap server does not bootstrap the Raft cluster again after a restart
- Implementing an endpoint for the leader to trigger restarts on its peers. This endpoint can trigger the follower to call a defined Unix signal (e.g.
ABORT) on itself. When catching this particular signal, it can ask the leader to demote itself and then call a non-zero exit code instead of asking to be removed from the cluster and exiting with exit code zero. - Adding a restart action in the reconciliation loop where nodes are sent restart calls serially
But that’s it! 😇 Adding this code will enable us to run fairly safe cluster restarts, minimising the risk of an inoperable cluster.
Thanks for reading, I hope you enjoyed it! Feel free to comment for any questions / clarifications. Otherwise have fun implementing your own Raft cluster! 😎
